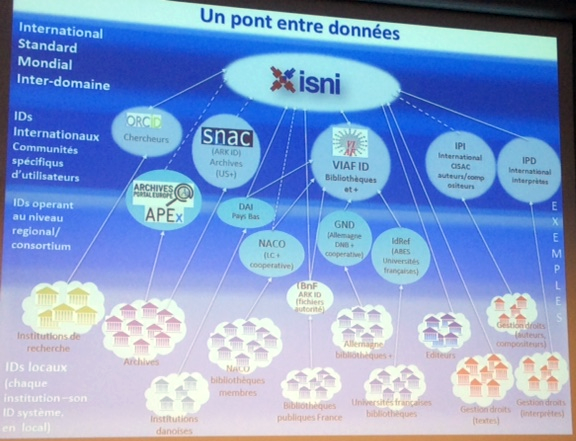
Am 17.11.14 fand in Paris ein Studientag zum Thema „Werkzeuge, Methoden, Korpora: die Modellierung von Daten in den Geistes –und Sozialwissenschaften“ statt. Organisiert und ausgerichtet von Emmanuelle Perrin im INHA, einem Zentrum für die Kunstgeschichte im Zentrum von Paris – sehr schön gelegen in der Nähe der alten BNF (Richelieu) – präsentierten sich 6 Projekte rund um das Thema Semantic Web Technologien (SWT) und Geisteswissenschaften. Dabei ging es nicht nur um kunsthistorische Projekte im engeren Sinne, sondern vielmehr um einen Überblick zu den zentralen Konzepten der digitalen Semantisierung von Daten, also Normdaten, kontrollierte Vokabularien, Ontologien und Linked Open Data (LOD). Eine zentrale Rolle bei der Umsetzung von Projekten mit SWT spielt in Frankreich die BNF und das CNRS. Beide Institutionen waren vertreten zum einen durch Antoine Isaac, dem Leiter der Abteilung Forschung und Entwicklung des Europeana-Projekts und zum anderen durch Didier Torny, dem stellvertretenden Direktor für Wissenschaftliche Information am InSHS, einer Abteilung des CNRS zur Unterstützung von Sozial- und Geisteswissenschaftlern in informationstechnologischen Dingen. Didier Torny stellte seinem sehr allgemein gehaltenen einführenden Beitrag (Données, corpus, publications : les enjeux de l’information scientifique et technique au CNRS à l’ère numérique) die drei wichtigen Organisationen bzw. Projekte bei der Unterstützung der Forscherinnen und Forscher vor: CLEO (Centre de l’edition electronique ouverte), Persée (ein Online-Zeitschriftenarchiv) und HumaNum, das Pariser Zentrum für Digital Humanities. Emmanuelle Perrin von der InVisu Gruppe des INHA, betonte die zentrale Rolle des Semantic Web für die langfristige und vor allem auch interoperable Bereitstellung von Daten und Forschungsergebnissen in den Geisteswissenschaften und stellte das eigene Projekt (STORM), eine Topographie der Stadt Kairo anhand europäischer Quellen, vor. Der Beitrag von Anila Angjeli (BNF) war hauptsächlich dem Thema Normdaten und hier speziell dem ISO Standard ISNI gewidmet, einem Versuch der BNF und der British Library, die verschiedenen nationalen Normdaten zu harmonisieren und zu integrieren. Obwohl der Ansatz sicher sehr zu begrüßen ist und offensichtlich gute Algorithmen für die Elimination von Dubletten und die Zuordnung der versch. Datensätze eingesetzt werden, bleibt doch das alte Problem vieler derartiger Projekte bestehen, dass (projekt-)relevante Personen im Datenbestand (immerhin inzwischen 8 Mio!) fehlen und nicht ohne weiteres beigefügt werden können. Der günstigste Weg ist hier eine Mitgliedschaft im ISNI Verband, der mit 800,- Euro/Jahr zu Buche schlägt.
Nach der Pause sprach René-Vincent Du Grandlaunay, der Direktor der Bibliothek des Dominikanerinstituts für Orientstudien in Kairo (IDEO) über das Modell FRBR (Functional Requirements for Bibliographic Records) zur Katalogisierung und seiner Anwendung auf die im Institut kuratierten Publikationen aus dem arabisch-islamischen Kulturkreis. Die detailverliebte Darlegung zeigte, wie hilfreich ein FRBR-Ansatz in einem Kontext sein kann, in dem Einzelausgaben aus vielen Jahrhunderten einem Werk zugeordnet werden müssen. Der letzte Beitrag des Vormittags von Matthieu Bonicel und Stefanie Gehrke war dem Europeana Projekt „Biblissima“ gewidmet, das sich mit der Modellierung der Überlieferungsgeschichte von Texten und Sammlungen im Mittelalter und der Renaissance beschäftigt. Die Modellierung erfolgt dort in CIDOC-CRM und FRBRoo und in der Präsentation konnten schon eine Reihe von interessanten Lösungen für die Modellierung von Sammlungen, aber auch von Inventaren und Katalogen vorgestellt werden.

Der Nachmittag war den Themen Linked Open Data (LOD), Ontologien für Historiker und einem Wörterbuchprojekt zum Wandel der Begrifflichkeit in der Kunstgeschichte zwischen 1600 und 1750 an der Universität von Montpellier gewidmet. Anne-Violaine Szabados (CNRS, ArScAn, UMR 7041, ESPRI-LIMC, Paris Ouest Nanterre La Défense) sprach über die Erfahrungen mit den Projekten LIMC und CLAROS, die beide dem Bereich der Archäologie zugeordnet werden können und auf die Vernetzung und Verlinkung mit LOD setzen. Francesco Beretta (CNRS, LARHRA, UMR 5190, Université de Lyon) stellte anhand des Historischen Projekts SyMoGIH (Système Modulaire de Gestion de l’Information Historique) die Probleme von Historikern bei der Suche nach einer passenden Ontologie für historische Ereignisse dar.

Das EU-geförderte Projekt LexArt, das von Flore César (CRISES, EA 4424, université Paul-Valéry, Montpellier 3) präsentiert wurde, steht noch anz am Anfang. Es versucht die Entwicklung von Kunstbegriffen in der Frühen Neuzeit anhand einer detaillierten Analyse von 300 Kunsttraktaten und Abhandlungen nachzuzeichnen, die anhand eines digitalen Werkzeugs gesammelt, analysiert und präsentiert werden sollen. Dies wird in Zusammenarbeit mit dem Trierer Zentrum für Digital Humanities realisiert werden, das entsprechend Expertise im Kontext digitalisierter Wörterbücher besitzt. Zum Abschluss fasste Mercedes Volait (InVisu, USR 3103 CNRS/INHA) die Ergebnisse des Tages noch einmal zusammen und erwähnte dabei auch einige der Themen, die nicht angesprochen werden konnten, wie z.B. die juristischen Fragen rund um LOD.
Insgesamt stellt sich für mich das Interesse an Semantic Web Technologien für geisteswissenschaftliche Projekte in Frankreich positiv da. Darauf weisen zumindest die besprochene Veranstaltung aber auch andere Aktivitäten in diese Richtung hin, die derzeit vor allem in Paris stattfinden. Am 12 Dezember wird dort z.B. eine Schulung „Einführung in das Semantic Web“ durch den früheren Leiter der Informatikabteilung der BNF, Romain Wenz, angeboten. Insbesondere die Ausrichtung von Europeana, die sich mit EDM auf ein graphenbasiertes Datenformat festgelegt hat, befördert die Akzeptanz und auch die Beschäftigung mit Semantik Web Technologien, gerade in den Geistes- und Sozialwissenschaften. Angebote wie data.bnf.fr erhöhen dabei die Sichtbarkeit und machen den konkreten Nutzen von Semantic Web Technologien evident.
Die Folien der Beiträge sind jetzt online unter: http://invisu.inha.fr/lundi-17-novembre-2014-Outils
Jörg Wettlaufer, Göttingen
Outils, méthodes, corpus : la modélisation des données en SHS.
Emmanuelle Perrin (InVisu, USR 3103 CNRS/INHA) : Présentation de la journée.
Didier Torny (directeur adjoint scientifique en charge de l’information scientifique et technique à l’InSHS) : Données, corpus, publications : les enjeux de l’information scientifique et technique au CNRS à l’ère numérique.
Première parti : Présidence de séance : Antoine Isaac (R & D manager, Europeana)
Anila Angjeli (BnF, département de l’information bibliographique et numérique) : ISNI – Les enjeux d’un identifiant international pour les personnes et les organismes.
René-Vincent Du Grandlaunay (directeur de la bibliothèque de l’Institut dominicain d’études orientales, Le Caire) : Le modèle FRBR appliqué au patrimoine arabo-musulman.
Matthieu Bonicel (BnF, coordinateur de Biblissima) et Stefanie Gehrke (coordinatrice métadonnées, Biblissima) : Biblissima et la modélisation de l’histoire de la transmission des textes et de la constitution des collections.
Seconde partie (Présidence de séance : Anila Angjeli)
Anne-Violaine Szabados (CNRS, ArScAn, UMR 7041, ESPRI-LIMC, Paris Ouest Nanterre La Défense) : L’expérience LIMC & CLAROS : pour l’élévation des données du patrimoine et de la culture dans le Linked Open Data.
Francesco Beretta (CNRS, LARHRA, UMR 5190, Université de Lyon) : Le projet SyMoGIH et le web de données.
Flore César (CRISES, EA 4424, université Paul-Valéry, Montpellier 3) : Modéliser le transfert des savoirs en Europe septentrionale aux xviie et xviiie siècles : l’exemple du projet LexArt.
Mercedes Volait (InVisu, USR 3103 CNRS/INHA) :Synthèse de la journée et discussion.