CDH Workshop: From Letters to Data. Digitizing 19th Century Student Travelogues, Groningen, 19.6.26, 9:00-12:00h (streamed)
Antworten


„Die Reihe Digitale Geschichte(n): Projekte und Praktiken der Digital History rückt jene Vorhaben in den Mittelpunkt, in denen digitale Methoden, Quellen und theoretische Reflexionen über Digitalität miteinander verbunden werden. Sie vereint Beiträge, die zeigen, wie vielfältig und breit die Digital History heute in Forschung und Praxis verankert ist, von der datenbasierten Analyse mittelalterlicher Quellen über die Visualisierung historischer Netzwerke bis hin zur Historisierung von Digitalität selbst. […]“
Bislang sind fünf Beiträge online. Darunter auch zuletzt der spannende und sehr lesenswerte Beitrag von Christopher Pollin über seinen Weg in und mit LLMs in Digital History Projekte.

 Jörg Wettlaufer / DALL-E 2024
Jörg Wettlaufer / DALL-E 2024
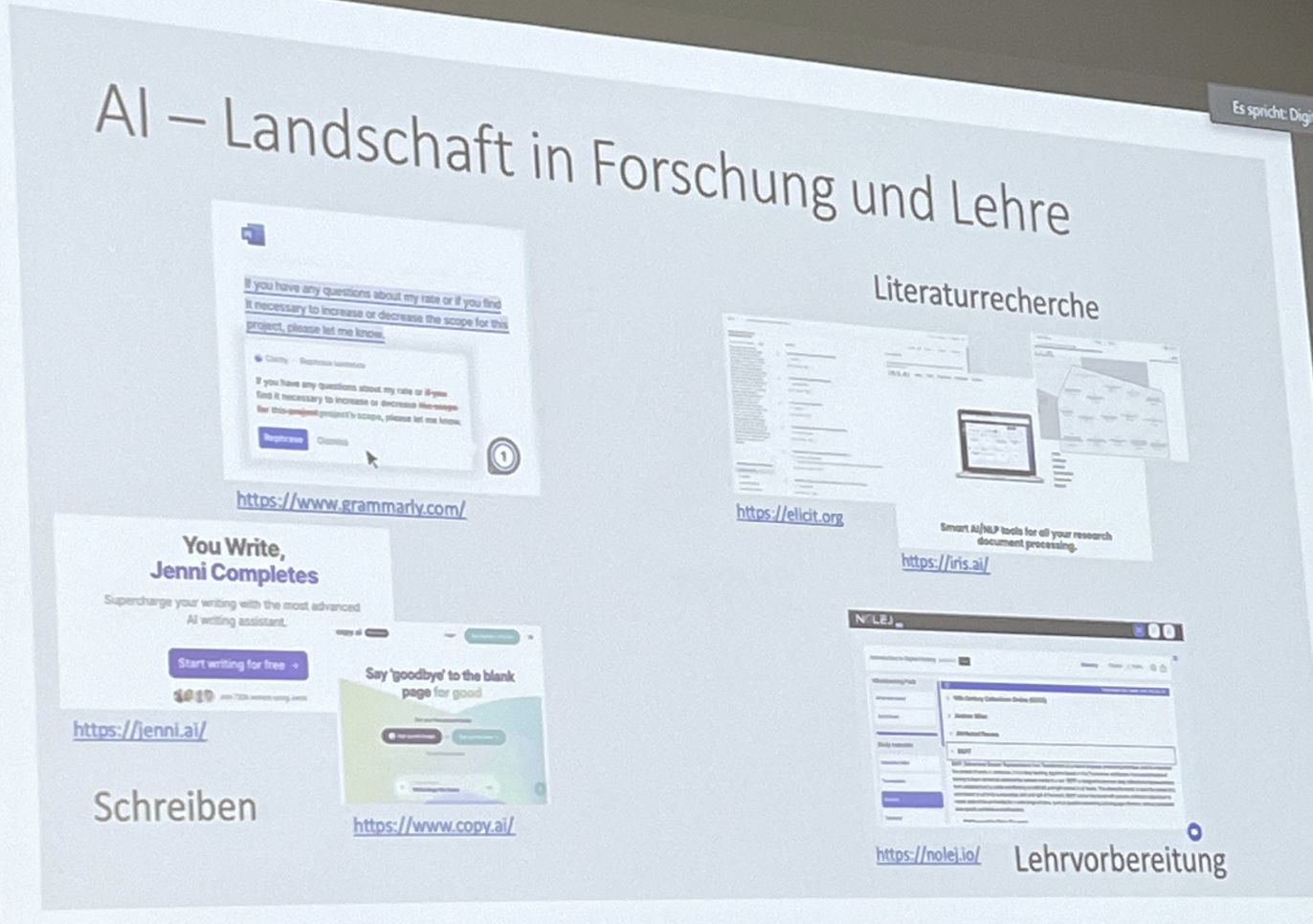
Um Methoden aus dem Bereich der Künstlichen Intelligenz adäquat in der Forschung anwenden zu können, ist es erforderlich, sie in ihren Grundzügen zu verstehen und idealerweise aktiv (spielerisch) zu erproben.
Die Themenkonferenz, die von der Akademie der Wissenschaften in Hamburg und der Niedersächsische Akademie der Wissenschaften zu Göttingen ausgerichtet wird, möchte sich diesem Spannungsfeld widmen. Teilnehmende aus den Akademievorhaben haben die Möglichkeit, die Potenziale neuer Methoden für die Analyse und Aufbereitung digitaler Ressourcen, speziell im Akademienprogramm, gemeinsam zu erörtern und zu erproben.
Das jeweils aktuelle Programm ist unter diesem Link verfügbar.
Vorläufiges Programm (Stand 20. August 2024):
Montag, 23. September 2024
ab 12:00 Ankunft der Teilnehmenden
12:45 Begrüßung
Workshop
13:00 – 17:00 Jan Kamlah, Thomas Schmidt (Mannheim)
eScriptorium
18:00 Öffentlicher Abendvortrag (Link)
Prof. Dr. Chris Biemann (Hamburg)
Where do you come from, ChatGPT? – Funktionsweise von Sprachmodellen
Dienstag, 24. September 2024
9:00 – 10:30 Integration von KI in Akademievorhaben: Projekte und Perspektiven
Matteo Burioni, Peter Bell (München)
Geplante KI-Anwendungen im Korpus der barocken Deckenmalerei
Wolfram Enßlin, Nathanael Philipp & Nadine Quenouille (Leipzig)
Forschungsportal BACH – Möglichkeiten der Integration von KI-gestützten Methoden
Jonatan Jalle Steller, Dominik Kasper (Mainz)
KI × DH: Zum Umgang mit ML, Transformern und LLMs in der Digitalen Akademie
10:30 – 11:00 Kaffeepause
11:00 – 12:30 OCR, HTR, Editionen und Urkunden
Daniel Kinitz (Leipzig)
ML-basierte Texterkennung arabographischer Handschriftenkataloge – Herausforderungen und Best Practices
Frederik Skidzun (Berlin)
Automatisierte Übersetzung von Urkundenregesten mit DeepL
Jörg Wettlaufer (Göttingen)
Custom-GPTs für die Entitäten-Erkennung und Auszeichnung
12:30 – 14:00 Mittagspause
14:00 – 15:30 Lexika, Übersetzungen und Annotation
Jan Christian Schaffert (Göttingen)
Edition, KI und Lexikographie – Wie können digitale und interdisziplinäre Zugänge zu der frühneuhochdeutschen Textwelt geschaffen werden?
Manuel Raaf (München)
Die Lemmatisierung von Zettelkästen mittels Deep Learning: Handschriftenerkennung im Fränkischen Wörterbuch
Patrick D. Brookshire (Mainz)
Namen erkennen und klassifizieren. Fine-Tuning von Transformer-Modellen
15:30 – 16:00 Kaffeepause
16:00 – 17:30 Retrieval Augmented Generation und Linked Open Data
Bärbel Kröger, Kaan Bashar (Göttingen)
Informationsextraktion aus lateinischen Texten des Repertorium Germanicum mittels Custom GPTs
Thomas Eckart, Felix Helfer, Uwe Kretschmer (Leipzig)
Machine-learning gestütztes Entity Linking
Timm Lehmberg, Stefano Valente (Hamburg)
Anwendungsbeispiel für dokumentbasiertes Parsing
19:30 Angebot einer Lichterfahrt auf der Elbe (Selbstzahler)
Mittwoch, 25. September 2024
Hands-On-Sessions
9:00 – 13:00 Timm Lehmberg (Hamburg)
Hackathon “Chat mit RAGgate”. Eigene Datenbasen mithilfe von Retrieval Augmented Generation zugänglich machen
9:00 – 13:00 Ines Röhrer (München)
Prompt-a-thon “Mein Bot versteht mich nicht!” Verarbeitung von Prompts verstehen und bessere Ergebnisse erzielen
Die Anmeldung ist für MitarbeiterInnen der Vorhaben aus dem Akademienprogramm und Akademiemitglieder online bis zum 31. August 2024 möglich unter: https://form.adwhh.de/index.php/898549?lang=de
(Vor der Anmeldung erfolgt eine Registrierung und Prüfung Ihrer E-Mail-Adresse)
Fragen zu Inhalt und Programm der Konferenz können an ki@akademie-der-wissenschaften-in-hamburg.de oder direkt an Timm Lehmberg (timm.lehmberg@awhamburg.de) gerichtet werden.

Vom 24.-26.5.2023 fand in Berlin die 2. Digital History Tagung der AG Digitale Geschichtswissenschaft im VHD hybrid statt. Nachdem die erste Tagung in Göttingen noch coronabedingt zunächst abgesagt und dann 2021 als reine Online-Tagung durchgeführt wurde, hatten sich diesmal 150 TeilnehmerInnen für den Präsenzteil und nochmal eben so viele für die Onlineteilnahme angemeldet. Ausgerichtet durch die Professur für Digital History von Torsten Hiltmann und tatkräftig von Melanie Althage und Martin Dröge unterstützt, hatte sich die Community der Digitalen HistorikerInnen zu diesem dreitägigen Treffen zu dem Thema “ Digitale Methoden in der geschichtswissenschaftlichen Praxis. Fachliche Transformationen und ihre
epistemologischen Konsequenzen“ an der HU Berlin eingefunden. Tagungsprogramm und Abstracts können auf der Tagungsseite auf hypotheses.org eingesehen werden. Der Tagung vorangestellt waren Workshops und eine Studierendenkonferenz am 23.5.23.
Da ich seinerzeit in Lille die initiale Idee zu diesem Tagungsformat hatte und die Etablierung des Formats dann zusammen mit Mareike König im Komitee der AG Digitale Geschichtswissenschaft voran getrieben habe, erlaube ich mir im folgenden einen kurzen Rückblick auf die gerade stattgefundene Tagung und einen Ausblick auf das nächste, schon für 2024 geplante Treffen.
Sowohl die Zahl der Anmeldungen als auch die rege Teilnahme in Berlin selber lassen darauf schliessen, dass das Format und auch die konkrete Umsetzung erneut einem aktuellen Bedürfnis in den Digitalen Geschichtswissenschaften entsprechen, sich über Methoden und epistemiologische Konsequenzen der Digitalisierung in den Geschichtswissenschaften im Rahmen eines engeren Fachbezugs zu verständigen. Die Beiträge waren auch diesmal qualitativ ansprechend und einem hohen theoretischen Reflexionsniveau, allerdings wurde auch kontrovers z.B. über Themen wie Restitution oder Postkoloniale Forschungsmethoden diskutiert. Thematisiert wurde auch der „Elefant im Raum“, den Patrick Sahle (Wuppertal) zunächst ansprach und der von Torsten Hiltmann im Abschlussplenum mit einem kurzem Input nochmal aufgenommen wurde. Es geht dabei um Large Language Models wie ChatGPT und deren disruptive Auswirkung auf Foschung und Lehre, auch in den Geschichtswissenschaften. Da der Elefant erst nach Abschluss des CfP zu dieser Tagung in den Raum getreten war, konnte er auf der diesjährigen Tagung noch nicht entpsprechnend adressiert werden. Das wäre für das nächste Treffen in Halle 2024 sehr wünschenswert.
Die Keynote in Berlin am Mittwochabend führte die TeilnehmerInnen in die Parallelwelt des Datenjournalismus. Hendrik Lehmann vom Tagesspiegel Innovation Lab sprach über Digital Journalism: Neue Methoden für Recherche, Visualisierung und Ausspielung in der journalistischen Arbeit. Dabei war interessant, welche Tools und Methoden in diesem Bereich eingesetzt werden, die möglicherwese auch in der Geschichtswissenschaftlichen Forschung von Interesse sein könnten.

Die Postersession der diesjährigen Tagung diente auch zur Vorauswahl der Finalisten für den Peter Haber Preis, der auf dem diesjährigen Historikertag in Leipzig vergeben wird. Sieben von dreizehn Poster wurden in einer kombinierten Publikums- und Juryabstimmung ausgewählt. Die Poster können auf dieser Seite online angeschaut werden. Gelungen war auch die Spreefahrt am Donnerstag, auf der die Diskussion vor der Kulisse der Hauptstadt und fortgesetzt werden konnte.

Zum Abschluss der Tagung erfolgte die Einladung zum nächsten Treffen in Halle im September 2024. Das Thema dort wird „Citizen Science“ sein und von Katrin Möller und KollegInnen von dem dortigen Datenzentrum ausgerichtet. Das Komitee der AG Digitale Geschichtswissenschaft freut sich schon auf Bewerbungen für die nächsten Tagungen, die dann im Wechsel mit dem Historikertag voraussichtlich 2026 und 2028 stattfinden werden.

Abstract: „[…] This study reflects some preliminary observations resulting from our digital history project that aims at building and digitally analyzing an extensive corpus
of English-, French-, and German-language travelogues about the nineteenthcentury
Ottoman Empire. It discusses our initial findings in travelogues regarding
the sociopolitical dynamics of the rise of Middle Eastern nationalisms and
our methodological suggestions about the opportunities as well as challenges
of employing digital tools to use travelogues for historical analysis. The chapter
starts with a discussion on nations and nationalisms in the nineteenth-century
Middle East, particularly in the Ottoman Empire. Then it deals with the question
of using travelogues as historical sources, focusing on the history of nationalisms,
and suggests that digital history tools are essential for increasing the reliability
of this body of sources. Finally, we present our findings and suggestions
on how and what kind of digital history tools can be used to open such corpora
to historical research.“
See also the project website:

Band 6 der Reihe „Studies in Digital History and Hermeneutics“ ist erschienen. Es handelt sich um den Tagungsband der Digital History Tagung, die die HerausgeberInnen im Frühjahr 2021 in Göttingen virtuell organisiert haben. Das Buch ist am 31. August 2022 Open Access erschienen! https://doi.org/10.1515/9783110757101 Enjoy.


Einreichungsfrist: Verlängert bis zum 19. Juli 2021
Auskünfte: Prof. Dr. Torsten Hiltmann und Dr. Mareike König,
Rückfragen: GW-digital [at] historikerverband.de
Einreichungen: https://phpdigigw21.sciencesconf.org/
Zum Historikertag 2021 schreibt die AG Digitale Geschichtswissenschaft im VHD zum ersten Mal gemeinsam mit dem VHD und dem Deutschen Historischen Institut Paris den Peter Haber Preis für digitale Geschichte aus. Prämiert werden Projekte, die einen innovativen Beitrag zum Gegenstandsbereich der digitalen Geschichtswissenschaft leisten. Einen epochalen oder methodischen Schwerpunkt gibt es nicht. Einreichungen sollen den Stand eines bereits laufenden Projekts der digitalen Geschichtswissenschaft anschaulich beschreiben. Eingereicht werden können Einzelprojekte (z.B. Dissertation) genauso wie Editions- und Infrastrukturprojekte oder Projekte zur Entwicklung von Tools. Die Projekte können sowohl die Theorie der digitalen Geschichte betreffen als auch Methoden- oder Praxisanteile beinhalten.
Weitere Informationen unter: https://digigw.hypotheses.org/3804
Am Donnerstag, dem 25.2.2021, ist im Rahmen der gerade laufenden Tagung Digital History 2021 eine Reihe von Workshops gestartet, die uns nun bis zum Sommer trägt. Marina Lemaire und Katrin Moeller aus der AG Digitale Geschichtswissenschaft im VHD haben die Reihe zusammen mit NFDI4memory organisiert und alle Informationen dazu finden sich auf der Seite:
Workshopreihe “Digitales Praxislabor Geschichtswissenschaft” #digigprx21
Hier ein kurzer Blick auf das spannende Programm:
Das Thema der diesjährigen Digital HistoryTagung am GHI lautet: „Datafication in the Historical Humanities: Reconsidering Traditional Understandings of Sources and Data“. Workshop und Tagung werden vom GHI in Zusammenarbeit mit dem C2DH, dem Lehrstuhl für Digital History an der HU Berlin sowie dem NFDI Konsortium NFDI4Memory, dem Roy Rosenzweig Centre for History and New Media sowie dem Department of History an der Stanford University organisert. Damit ist so ziemlich alles genannt, was Rang und Namen in den Digitalen Geschichtswissenschaften in Deutschland, Luxemburg und den USA hat. Das erzeugt Erwartungen und weckt Vorfreude. Alle Informationen und den Call findet man unter:
Die Tagung soll je nach Corona-Situation klassisch vor Ort (mit Reisestipendien), hybrid oder ganz virtuell stattfinden. Der Termin ist allerdings fix.
Für die Tagung wird die Spannung zwischen dem historischen Quellenbegriff und der Datenzentrierung der Digital Humanities thematisiert bzw. instrumentalisiert. Dabei wird das Fehlen eines weithin akzeptierten konzeptionellen Frameworks für die Modellierung und Kuratierung von Daten in der Digital History konstatiert. An dieser Stelle ist vielleicht ein Hinweis auf die Data for History Initiative ( http://dataforhistory.org/ ) angebracht, die seit 2017 (u.a. vorbereitet durch den Workshop „Semantic Web Applications in the Humanities“ in Göttingen 2012 und 2015) versucht, z.B. das CIDOC-CRM in eben diese Richtung zu erweitern und für die Historischen Wissenschaften nutzbar zu machen. Jedenfalls ist es zutreffend, dass eine solche Konzeptionalisierung immer kulturgebunden ist und ein generalisierendes Modell dem Rechnung tragen müsste. Insgesamt ein sehr spannendes Thema, das interessante Diskussionen erwarten läßt.

Es ist höchste Zeit, Digitalisierung und Nachhaltigkeit im Zusammenhang zu betrachten und ihr spannungsreiches Verhältnis mit Wissenschaft und Öffentlichkeit gemeinsam zu diskutieren. Die interdisziplinäre virtuelle Konferenz „nachhaltig digital – digital nachhaltig“ am 4./5. Dezember 2020 in der Reihe „Wissenschaft für Frieden und Nachhaltigkeit“ von Universität Göttingen, Vereinigung Deutscher Wissenschaftler e.V. (VDW) und Stiftung Adam von Trott lädt dazu ein.
Den Einführungsvortrag hält der Techniksoziologe Felix Sühlmann-Faul. Mitdiskutieren kann man in zehn virtuellen Workshops (Webinare). Thematisiert werden aktuelle Entdeckungen und neu entstehende Potenziale in Wissenschaft und Technologie für eine nachhaltige Entwicklung in den Bereichen Mobilität, Energie, Landwirtschaft, Forst, Künstliche Intelligenz und den Geisteswissenschaften. Ein weiterer Schwerpunkt liegt auf gesellschaftlichen Prozessen, die durch die Digitalisierung ganz wesentlich verändert werden. Die Themen reichen hier von der Veränderung der Arbeitswelt, Demokratisierungsprozessen und dem massiven wirtschaftlichen Strukturwandel bis hin zum neuen Digital Education Action Plan der EU und Gamification.
Am 4. Dezember startet um 16:00 Uhr das Panel „Nachhaltige Digitale (Geistes)Wissenschaft„. Die Geisteswissenschaften nehmen seit geraumer Zeit an der digitalen Transformation von Wissenschaft und Gesellschaft teil. Mit großen Erwartungen und auch finanziellem Aufwand werden Forschungsumgebungen und Repositorien gefördert, die die Arbeit in den Geisteswissenschaften teilweise eine neue Qualität verleihen. Aber wie steht es mit der Nachhaltigkeit dieser Forschungsinfrastrukturen? Führen die Projektförderungen im Zusammenhang mit rasant schnellen Entwicklungen in der angewandten Informatik und die dem Digitalen immanente Immaterialität zu einer Situation, in der viele Ressourcen schneller wieder verschwinden als sie entstehen? Welche Rolle spielt die Nationale Forschungsdaten Infrastruktur (NFDI) in diesem Zusammenhang und welche Konzepte haben ihre Konsortien, um eine nachhaltige Bereitstellung der Forschungsdaten und digitalen Ressourcen zu gewährleisten? Diese und weitere Fragen sollen im Rahmen des Workshops diskutiert und erörtert werden.
Moderation
Dr. Jörg Wettlaufer, Akademie der Wissenschaften zu Göttingen
Impulse
Prof. Dr. York Sure-Vetter, Direktor Nationale Forschungsdaten Infrastruktur (NFDI) / Karlsruher Institut für Technologie
Dr. Christian Hänger, Bundesarchiv
Dr. Klaus Schindel, Bundesministerium für Bildung und Forschung
Prof. Dr. Patrick Sahle, Bergische Universität Wuppertal
Die gesamte Veranstaltung findet als Videokonferenz (Zoom) statt und steht allen Interessierten ohne Teilnahmegebühr offen. Mehr Informationen zum Programm und zur Anmeldung auch für einzelene Workshops auf
www.uni-goettingen.de/nachhaltigkeitskonferenz.

Georg-August-Universität Göttingen | Abteilung Öffentlichkeitsarbeit | Benjamin Bühring | Wilhelmsplatz 1 | D-37073 Göttingen | benjamin.buehring@zvw.uni-goettingen.de
www.uni-goettingen.de/nachhaltigkeitskonferenz
Die Konferenzreihe „Wissenschaft für Frieden und Nachhaltigkeit“ wird von der Universität Göttingen seit 2012 in Kooperation mit der Vereinigung Deutscher Wissenschaflter e.V. (VDW) und der Stiftung Adam von Trott, Imshausen e.V. organisiert. Sie hat zum Ziel einen Dialog zwischen Wissenschaft und allgemeiner Öffentlichkeit über gesellschaftlich relevante Themen zu ermöglichen.
