

Seit einigen Monaten beschäftige ich mich im Kontext der Digitalen Geschichtswissenschaft intensiver mit einem Softwarebundle mit dem Namen Open Semantic (Desktop) Search (OSDS) und möchte meine Erfahrungen gerne teilen. Zunächst einmal – worum handelt es sich? OSDS ist eine freie Software, die nur aus Open Source Bestandteilen zusammengestellt wurde und auf dieser Grundlage als Donationware weiter entwickelt wird. Das Projekt stammt aus dem Journalismus und spezieller aus dem Bereich des investigativen Journalismus, der sich heutzutage mit teilweise riesigen Datenmengen (Stichwort: Panama Papers) auseinander setzen muß.

Der Entwickler hinter OSDS ist Markus Mandalka, der sich selber als Journalist und Informatiker bezeichnet. Auf seiner Homepage stellt er sich als politisch eher links orientiert dar – ein Detail, das mir sein Softwarebundle noch sympathischer macht. Zwar bin ich als Historiker mit Spezialisierung auf das späte Mittelalter nicht so auf Datenschutz, Privatheit und Anonymität aus, wie das im investigativen Journalismus der Fall sein mag, aber es schadet natürlich auch nicht, dass Markus Mandalka sein Softwarebundle auch als verschlüsseltes und auf USB-Stick betreibbares Livesystem unter dem Namen InvestigateIX anbietet. Ich beschäftige mich im folgenden aber nur mit den drei! anderen Varianten, die er über die Webseite www.opensemanticssearch.org und ein dazugehöriges github-repository anbietet:
1. Open Semantic Desktop Search
2. Open Semantic Search Appliance
3. Open Semantic Search Server (Package)
Paket 1 ist eine VM Appliance, die man mit Oracle Virtual Box laden und lokal auf einem Rechner betreiben kann. Die Appliance wird in zwei Varianten zum Download angeboten: einmal mit englischen und einmal mit deutschen Keyboard Settings. Beide Varianten sind relativ aktuell (Juli bzw. August 2018). Das Projekt selber scheint seit drei oder vier Jahren zu bestehen. Das alleine ist schon eine Leistung für ein Softwarepaket des Umfangs und der Leistensfähigkeit von OSDS, das von nur einer Person gepflegt und weiterentwickelt wird.
Die zweite Variante ist ebenfalls eine Appliance, die ebenfalls unter Oracle Virtual Box läuft, aber nur einen Server als localhost bereit stellt. Dort fehlt der „Desktop“ im Debian Linux, auf dem beide Distributionen aufsetzen. Wie das so bei virutuellen Maschinen für Virtual Box üblich sind, bringen die Appliances ein gewisses Gewicht auf die Waage. Die OSDS Version schlägt mit 3GB zu Buche, die Servervariante OSS mit (nur) 1.8 GB. Das dritte Paket (OSSS) ist mit etwa 300 MB am Leichtgewichtigsten, aber erwartet natürlich auch eine (manuelle) Installation und vor allem Konfiguration auf einem Debian oder Ubuntu basierten System. Letzteres habe ich bislang noch nicht ausprobiert – ich beschränke meinen Bericht daher auf die ersten beiden Varianten, die komfortabel in Virtual Box laufen.
Bevor wir zur eigentlichen Installation kommen, vorab noch einige Informationen zum Leistungsumfang des Pakets und warum es sich überhaupt lohnt, sich damit zu beschäftigen. Kernstück der Enterprise Suchmaschine ist ein Lucene SOLR Indexer (Elastic Search ist ebenfalls verwendbar), mit dem recht beliebige Dokumente indexiert werden können. Die enthaltenen Informationen werden damit als Keyword im Kontext findbar und referenzierbar. Aber OSDS ist noch wesentlich mehr. In dem Paket ist auch ein sogenanntes Open Semantic ETL (Extract-Transform-Load) Framework integriert, in dem die Texte für die Extraktion, Integration, die Analyse und die Anreicherung vorbereitet werden. Es handelt sich um eine Pipeline, die einem sehr viel von Arbeit hinsichtlich der Bereitstellung der Texte für den Indexer abnimmt. Wer mit Lucene/Solr arbeitet weiß, wie viel Zeit die Aufbereitung der Daten in der Regel beansprucht. OSDS nimmt einem sehr viel davon ab und kümmert sich nach dem Prinzip eines überwachten Ordners um sämtliche Schritte, die von der Extraktion über die linguistische Analyse bis zur Anreicherung mit weiteren Metadaten notwendig sind. Schliesslich stellt das Paket auch einen Webservice (Rest-API) für die maschinelle Kommunikation sowie ein durchdachtes User Interface zur Verfügung, mit dem die Suchmaschine bedient, konfiguriert und natürlich auch durchsucht werden kann. Die facettierte Suche spielt dabei eine besondere Rolle, da die Facetten mehr oder weniger automatisch aus der linguistischen Analyse der Texte und auf der Grundlage von (konfigurierbaren) Namen Entities (Personen, Orte, Organisationen etc.) gebildet werden. Entsprechend sind auch die Hauptfunktionen des Softwarepakets angelegt: Sucheninterface, ein Thesaurus für Named Entities, Extraktion von Entitäten in neu zugefügten Texten, eine listenbasierte Suche sowie eine Indexfunktion, die den Aufbau des Suchindex neu anstößt. Und das alles in einem einfach zu bedienden Userinterface, das mit der Maus bedient werden kann.
Wer nun neugierig oder enthusiastisch geworden ist, dem sei gesagt, dass es wie meist im Leben einen Wermutstropfen gibt: insbesondere OSDS aber auch OSS brauchen gewisse Ressourcen, um ihre Arbeit effizient verrichten zu können. Als Mindestausstattung für einen Betrieb unter Orcale Virtual Box gebe ich 8 GB RAM und (der Größe des Projekts entsprechend) ausreichend Speicherplatz auf einer SSD an. Auf einem immerhin mit 8GB ausgstatteten Notebook mit Doppelkernprozessor der Core Duo Reihe ist es mir nicht mehr gelungen, in vertretbaren Zeiten einen Index zu produzieren. Allerdings waren meine Testdaten auch recht umfangreich (25 GB PDF Dateien mit zehntausenden von Seiten). Alternativ kann man sich, bei schwacher Hardware, eines Tricks bedienen und den Index auf einer schnellen Maschine (aktueller Mehrkernprozessor mit möglichst üppigem RAM) erstellen lassen und dann beides (Appliance und Solr-Index) auf das betreffende Gerät zurückspielen. Meist reicht dann die Performance, um zumindest die Suchfunktionalität auch auf schwächerer Hardware zu ermöglichen. Ein weiterer Ressourcenfresser beim Anlegen des Index ist OCR. OSDS hat Tesseract als eigene OCR Egine inkl. (hört hört) Frakturerkennung! integriert. Wenn man seine PDF Dokumente aber vor der Indexierung erst noch mit der OCR behandelt, kann man den Rechner bei entsprechender Materialfülle gerne mal ein oder zwei Tage durchrödeln lassen, bevor sich (hoffentlich) ein brauchbares Ergebnis zeigt. Daher rate ich (ebenso wie der Entwickler es tut) dazu, OCR erst mal abzustellen, wenn man es nicht unbedingt braucht (geht im Konfigurationsmenue) und den Index zunächst mal nur mit schon vorhandenen Textlayern oder am besten mit Dokumenten zu füttern, die eh nur aus Text bestehen. Dabei ist die Suchmaschine recht offen für Formate und bringt eine Menge Filter mit, die den Text extrahieren können (hier mal die Liste von der Webseite kopiert: text files, Word and other Microsoft Office documents or OpenOffice documents, Excel or LibreOffice Calc tables, PDF, E-Mail, CSV, doc, images, photos, pictures, JPG, TIFF, videos and many other file formats). Im Hintergrund werkelt hier natürlich Apache Tika.
I. Getting started: Für unser Hands on workshop wollen wir OSDS auf einem aktuellen Gastsystem installieren. Dazu nehmen wir die Version mit den Deutschen Keyboard. Das spart einige Einstellungen und Probleme mit der Einrichtung. Bevor wir starten können, benötigen wir Oracle VM mit dem Extensionpack. Die Software kann man für verschiedene Betriebsysteme auf dieser Seite herunterladen. Dann wird zuerst VB und anschliessend werden die Erweiterungen mit VB geöffnet und installiert. Virtual Box benötigt einige Virtualisierungserweiterungen der aktuellen Intel-CPUs mit der Bezeichnung VT-x und dessen AMD-Pendant AMD-V. Hierbei werden auch neuere Funktionen dieser Befehlssatzerweiterungen wie Nested Paging/Rapid Virtualization Indexing unterstützt. Was Virtual Box gar nicht mag ist, wenn man Hyper-V aktiviert hat. Das muss man dann erst im BIOS wieder ausstellen, da sich beide Virtualisierungssysteme sonst um die Ressourcen streiten würden. Da Microsofts Hyper-V gewissermaßen im Heimvorteil ist, hat Virtual Box dann keine Chance. Wenn alles korrekt eingerichtet ist, können wir einen Blick auf das Hauptmenue von Virtual Box werfen. Dort können wir unter Datei den Menuepunkt Appliance Importieren finden, der uns die Auswahl der zuvor gespeicherten oder heruntergeladenen OSDS Datei erlaubt (Achtung – bei MacOS sind die Menuepunkt ganz oben im Finder, nicht im VB Manager!) .

Wenn man auf weiter klickt, erhält man einen Überblick der Einstellungen der virutellen Maschine. Dies kann man ggf. anpassen, aber das ist auch später noch über das Menue „Ändern“ in Virtual Box möglich.

Achtung. Diese Einstellung mit 5 GB RAM wird nur funktionieren, wenn das Gastgebersystem mindestens über 8 GB verfügt! Je niedriger man hier die Einstellung wählt, je zäher läuft das System hinterher und um so länger dauert der Aufbau des Index. Zusätzliche CPUs sind übrigens der Geschwindigkeit auch sehr zuträglich. Wenn man dann auf importieren klickt, dauert es etwa 2 bis 3 Minuten, bis die virutelle Festplatte angelegt ist. Nun ist es wichtig, zumindest einen gemeinsamen Ordner anzulegen, den Host und Gast, als die gerade eingerichtete OSDS VM, gemeinsam nutzen. Dazu einfach einen beliebigen Ordner an einem beliebigen (aber besser lokalen) Ort anlegen oder einbinden.
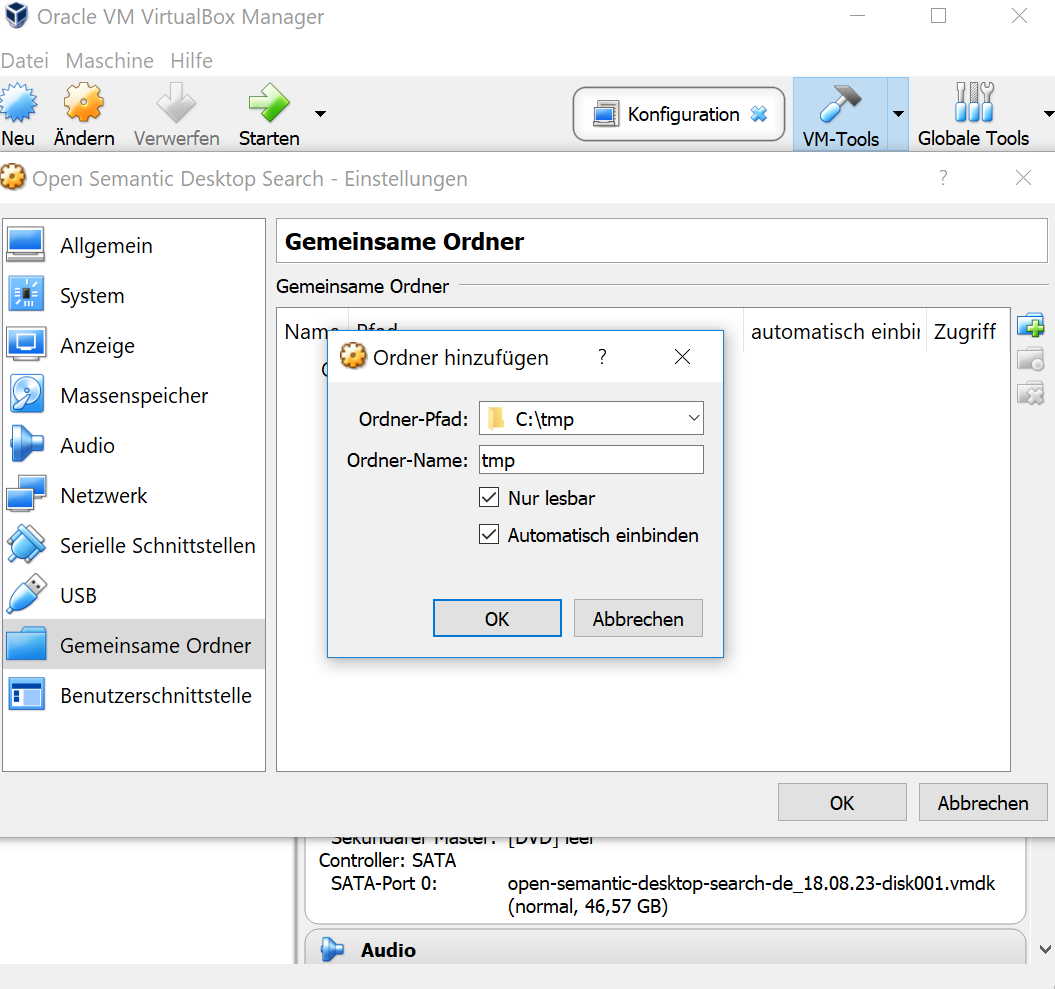
Ich habe hier z.B. den Ordner tmp auf dem Laufwerk C: unter windows angelegt und die Häkchen bei „nur lesbar“ und „automatisch einbinden“ gesetzt. Damit kann das Gastsystem auf Dateien zurückgreifen, die in diesem Ordner abgelegt sind. Für diesen Workshop habe ich zwei PDF Dateien herausgesucht, die als Beispiel dienen und den Aufbau des Suchindex demonstrieren sollen.
- https://adw-goe.de/fileadmin/forschungsprojekte/resikom/dokumente/pdfs/residenzenforschungen_15_I_1.Teilband.pdf
- http://adw-goe.de/fileadmin/dokumente/forschungsprojekte/resikom/pdfs/residenzenforschungen_15_I_2.Teilband.pdf
Diese Dateien müssen in den angelegten geteilten Ordner heruntergeladen werden, damit sie anschliessend von OSDS indexiert werden können.
Es gibt eine spezielle Voreinstellung bei OSDS, die man kennen sollte. Wenn man auf Laufwerk C einen Ordner namens index anlegt und auf die folgende Weise einbindet, dann wird der SOLR Index nicht in der VM, sondern in diesem Ordner im Gastsystem gespeichert. Das kann verschiedene Vorteile haben (die Festplatte der VM wird nicht unmäßig groß und man kann den index Ordner einfach von einem zum anderen Rechner übertragen). Ich nutze dieses Feature gerne, da es die Anwendung noch flexibler macht.

Der Index-Ordner muss selbstverständlich auch schreibbar sein und sollte am besten auch automatisch eingebunden werden, damit OSDS beim Start gleich alle wichtigen Ressourcen beeinander hat.
Das war es eigentlich schon. Nun können wir die VM zum ersten Mal starten und OSDS laufen lassen. Nach einiger Zeit sollte zunächst Debian und dann der Firefox ESR starten und ein UI mit der Suchmaske anzeigen. Die ist momentan noch leer, da eine entscheidende Information noch fehlt: der Ort der Dateien oder Ressourcen, die Indexiert werden sollen. Dies wird im Menuepunkt Datasources -> Files and Directories (Filesystem) eingestellt.
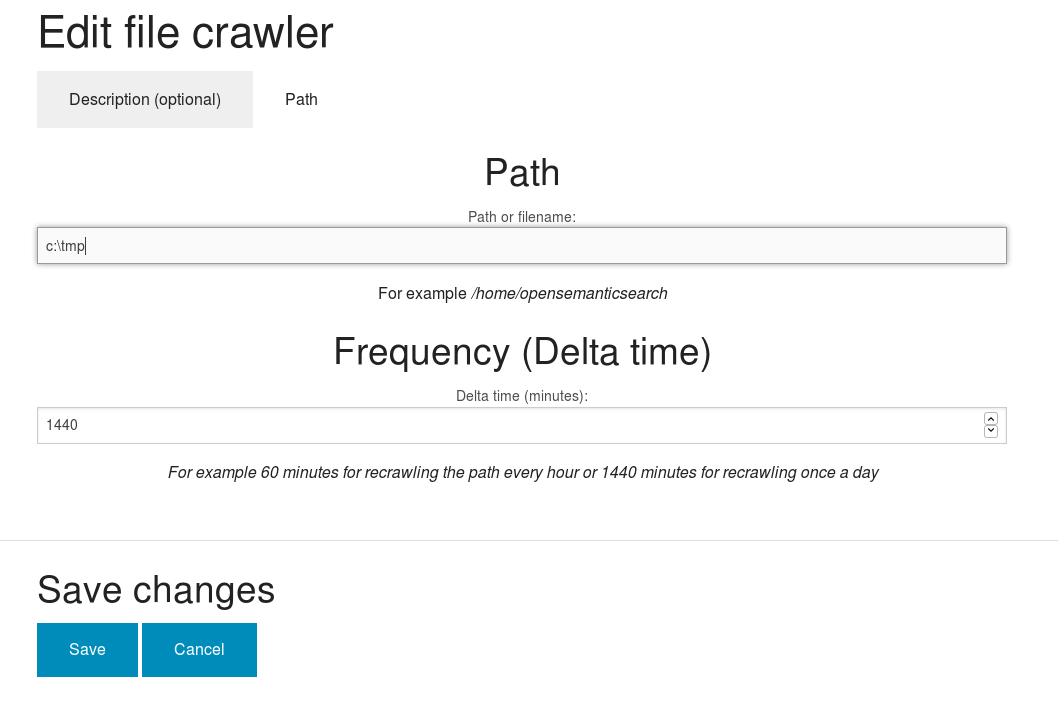
Sobald dies gespeichert ist, kann man den entsprechenden Ordner indexieren lassen und erhält nach einem reload der Suchmaske das Ergebnis. Mit Blick auf die indexierbaren Ressourcen ist bemerkenswert, dass neben Dateien im Filesystem der VM oder des Hosts auch Webseiten (ein oder mehrmals im Intervall), Newsfeeds, Tabellen (csv) und sogar Annotationen aus hypothes.is mit in den Index aufgenommen werden können. Die Ergebnisse können als Liste, als Vorschau (des Suchergebnisses im Volltext) , als Enitäten oder auch im entsprechenden Medienformat ausgegeben werden. Eine Geovisualisierung und weitere Analysetools stehen ebenfalls zur Verfügung.
Bei der ersten Suche fällt sogleich auf, dass die Ergebnisse in der Listenansicht als KWIC (Keyword in Context) angezeigt werden, aber von dort leider kein direkter Zugriff auf die einzelnen Funstellen möglich ist. Das hängt mit der Indexierung zusammen. Hätten wir jede Seite der Dokumente einzeln indexiert, könnten wir nun auch einzeln darauf zugreifen. So erhalten wir nur eine dokumentweise Ausgabe, bei der wir dann noch per Hand zu den Fundstellen navigieren müssen. Immerhin können wir mit einem Klick das Dokument laden oder auch den Volltext (Vorschau) anzeigen lassen. Wer eine Seitenweise Indexierung (doppelte Indexgröße) bevorzugt, kann dies hier einstellen:

Damit kennen wir nun die Grundfunktionalität des OSDS und können uns dem Thema Annotation und Tagging widmen, das besonders spannend ist. Übrigens, wenn wir den erstellten Index wieder löschen wollen, dann müssen wir auf die Kommandozeile des Debian OS gehen und dort opensemanticsearch-delete –empty eingeben. Anschliessend ist der Index wieder leer wie direkt nach der Installation.

Wem das zu umständlich ist (und wer genug Platz auf seinem Speichermedium besitzt), kann natürlich auch einen Snapshot von der VM erstellen, auf die man dann bei Bedarf zurückgreifen kann.
Eine zusätzliche Steuerungsebene direkt auf OS Ebene bietet das GUI, das sich hinter dem Reiter Aktivitäten (ganz oben link) verbirgt.
![]()
Die Lupe öffnet den Browser und das Suchfenster, das Listensymbol führt zur listenbasierten Suche (ein feature, das ich mir schon länger für Digitale Bibliotheken wünsche!) . Das Buch öffnet das Thesaurus Managment für Named Entities und das Symbol des geöffneten Ordners steht schliesslich für den Start des Indexdienstes. Mit dem Extraktionstool kann man Entitäten auch noch nachträglich in vorhandenen Datensammlungen taggen und der Aktenschrank führt schliesslich auf das Dateisystem der GastVM. Es handelt sich ja um eine VM mit Gnome Desktop und allem, was so dazu gehört. Übrigens hat die VM die Nutzer root und user. Das Passwort für user ist „live“ und für root ist keins gesetzt. Das macht durchaus Sinn, wenn man in Virtual Box arbeitet und die VM vor Zugriffen von aussen geschützt ist. Wenn man aber die Serverversion installieren und produktiv betreiben möchte, sieht die Sache schon anders aus. Spätestens dann sollte man die voreingestellten Passworte ändern und dafür sorgen, dass ein administrativer Zugriff von aussen nicht mehr ohne weiteres möglich ist.
Die ausführlichste Anleitung (auf Englisch) findet sich (natürlich) auf der Seite www.opensemanticsearch.org. Es gibt dort auch eine deutsche Version, aber meist sind nur die Überschriften übersetzt. Zusätzlich kann man bei Problemen noch auf die Github-Seite des Projekts gehen, um Lösungsvorschläge zu finden.
II. Using OSDS: Nachdem die VM läuft, möchte man natürlich ausprobieren, was OSDS alles bietet. Das ist recht viel. Durch die Integration verschiedener NLP Tools und der Bereitstellung von Schnittstellen zum Semantic Web sind die Möglichkeiten ziemlich weit gesteckt, die gesammelten und idexierten Daten anzureichern, zu analysieren und schliesslich zu finden, was man (zumindest in den Geisteswissenschaften) eigentlich sucht: nämlich eine ganz bestimmte Information zu einer sehr speziellen Fragestellung. Ich möchte im folgenden auf einige der oben schon angesprochenen Möglichkeiten zur Aufbereitung und Erschließung von Daten eingehen und werde diesen Blogeintrag kontinuierlich ergänzen, sobald ich weitere Möglichkeiten entdecke bzw. ausprobiere.
a) Entitäten, Worte, Konzepte als Facetten zufügen. Diese Funktion erlaubt ein sehr präzise auf die Fragestellung gerichtetes Tagging der Daten. Wenn man ein neues Konzept hinzufügt, dann versucht OSDS sofort dieses in den Texten zu finden und entsprechend auszuzeichnen. Wenn man dort also etwas eingibt, was häufiger vorkommt, kann der update des Index schon einige Sekunden dauern.

Wem das zu mühselig erscheint und wenn man evtl. schon eine Liste von Namen oder Konzepten zur Verfügung hat, die im Zusammenspiel mit den Daten hilfreich ist, der kann auch ganze Listen, kontrollierte Vokabularien oder Ontologien hochladen, die dann auf die Daten angewendet werden. Das Format der Liste wird i.d.R. erkannt. So ist es zum Beispiel möglich einfache Namen bzw. Ortslisten im CSV Format in Exel abzuspeichern und zu importieren. Aber auch RDF, SKOS und OWL werden unterstützt. Je nach Umfang der Daten und Listen ist hier mit einer längeren Bearbeitungzeit zu rechnen.

In der voreingestellten Konfiguration versucht OSDS Autoren, Personen, Organisationen, Orte, Emailadressen und die Dokumentensprache zu erkennen. Dazu nutzt das Framework in der Voreinstellung das SpaCy NER tool, zur Auswahl steht aber auch Standford NER Tagger, mit dem das Taggen aber wohl erheblich länger dauert. Den Autor versucht OSDS aus den entsprechenden Metadaten der Dokumente zu extrahieren. Wenn dort also etwas nicht der Autor des Textes, sondern der Setzer der Druckerei sich verewigt hat, dann erhält man auch dieses Ergbnis in den Facetten zurück. Für Historiker (zumindest des Spätmittelalters) relativ sinnfrei ist auch das Erkennen von email-Adressen oder von Geldmengen (wenn man nicht gerade Wirtschaftshistoriker ist). Wie immer bei NER sind die automatisch gewonnenen Ergebnisse weit von perfekt und man muß relativ tolerant sein, um die generierten Facetten trotz der vielen fehlerhaften Einträge produktiv zu nutzen.
Viel präziser und effektiver ist das Tagging über die bereitgestellten Werkzeuge. Hier kann man z.B. aufgrund einer Suchabfrage ein Label vergeben, das dann unter der gewünschten Facette aufgenommen wird, obwohl der Begriff möglicherweise gar nicht im Text vorkommt. Eine genaue Anleitung zur Verwendung findet man hier. Einige mögen sich nun fragen, was genau das Semantische an Open Semantic Search sei. Mit der NER Funktionalität ist ja schon ein erster Schritt in diese Richtung getan. Aber OSDS hat diesbzüglich noch wesentlich mehr zu bieten. Neben der Bereitstellung von neo4j gibt es verschiedene Möglichkeiten, Linked (Open) Data für die Anreicherung der eigenen Daten zu importieren oder auch die eigenen Ergebnisse als RDF zu exportieren. Ich möchte hier ein Beispiel vorstellen, dass der Entwickler selber beschreibt, nämlich den Import von Entitätenlisten aus Wikidata.
Im Rahmen dieses Hands-on können nicht alle Möglichkeiten von OSDS vorgestellt werden. Ich hoffe die Beispiele haben verdeutlicht, welche Potentiale dieses Werkzeug bietet und zum selber ausprobieren und zur Weiternutzung angeregt. Viele Anregungen zum Betreiben eigener Suchmaschinen bietet Markus Mandalka auch auf seiner persönlichen Webseite https://www.mandalka.name.
Pingback: Praxislabor Digitale Geschichte beim Historikertag in Münster: Spotlights und Hands-on-Workshops #histag18 – Digitale Geschichtswissenschaft