Am 25.3.19 findet ein Workshop zu Open Semantic (Desktop) Search (OSDS) auf der DHd in Mainz statt. We are so exited :-). Er basiert auf dem Hands On, der auf dem Historikertag 2018 in Münster durchgeführt wurde. Dieser Blogbeitrag leitet durch die Installation von OSDS und stellt Nutzungsbeispiele vor.
Die zugehörigen Slides für den Workshop finden Sie hier.
Zunächst einmal – worum handelt es sich? OSDS ist eine freie Software, die nur aus Open Source Bestandteilen zusammengestellt wurde und auf dieser Grundlage als Donationware weiter entwickelt wird. Das Projekt stammt aus dem Journalismus und spezieller aus dem Bereich des investigativen Journalismus, der sich heutzutage mit teilweise riesigen Datenmengen (Stichwort: Panama Papers) auseinander setzen muß/möchte.

Der Entwickler hinter OSDS ist Markus Mandalka, der den Workshop mit ausrichtet und in den letzten Tagen auch ein neues Release von OSDS vorbereitet hatte. Open Semantic Search kann man auf der oben verlinkten Seite von Markus Mandalka in drei Varianten, die er über die Webseite www.opensemanticssearch.org und ein dazugehöriges github-repository anbietet, herunterladen:
1. Open Semantic Desktop Search
2. Open Semantic Search Appliance
3. Open Semantic Search Server (Package)
Paket 1 ist eine VM Appliance, die man mit Oracle Virtual Box laden und lokal auf einem Rechner betreiben kann. Für den Workshop wurde die VM auf den aktuellen Stand von Virtual Box (6.0.4.) angepaßt. Die Appliance wird in zwei Varianten zum Download angeboten: einmal mit englischen und einmal mit deutschen Keyboard Settings. Die deutsche Version wurde vor kurzem aktualisiert (08.04.19). Die anderen Versionen sind teilweise noch auf dem Stand von Dezember 2018. Für den workshop nutzen wir die aktuelle deutsche Version.
Die zweite Variante ist ebenfalls eine Appliance, die ebenfalls unter Oracle Virtual Box läuft, aber nur einen Server als localhost bereit stellt. Dort fehlt der „Desktop“ im Debian Linux, auf dem beide Distributionen aufsetzen. Wie das so bei virutuellen Maschinen für Virtual Box üblich sind, bringen die Appliances ein gewisses Gewicht auf die Waage. Die OSDS Version schlägt mit etwa 3GB zu Buche, die Servervariante OSS mit (nur) 1.8 GB. Das dritte Paket (OSSS) ist mit etwa 300 MB am Leichtgewichtigsten, aber erwartet natürlich auch eine Installation und vor allem Konfiguration auf einem Debian oder Ubuntu basierten System. Letzteres haben wir inzwischen ausprobiert und es hat auch gut funktioniert: https://teaching.gcdh.de/search/ .
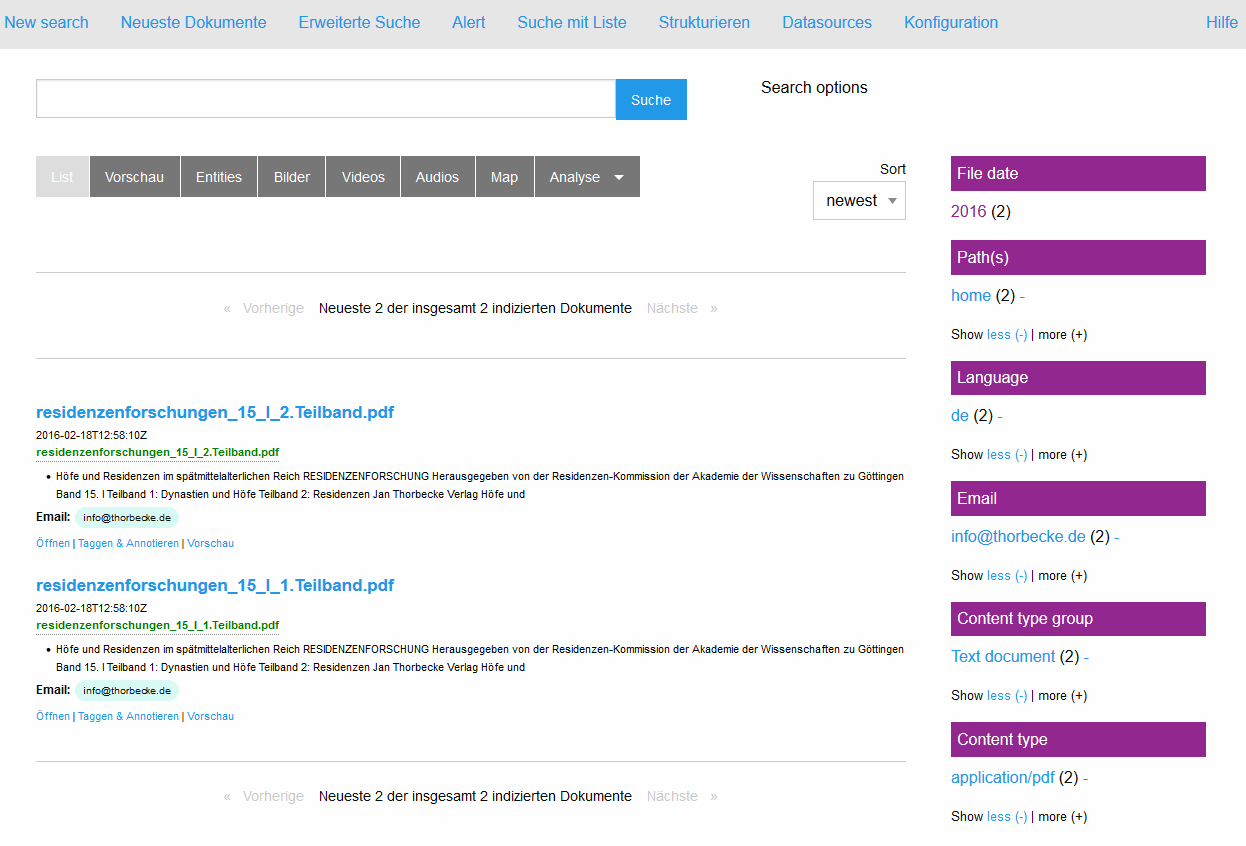
Bevor wir zur mit der Installation von OSDS beginnen, vorab noch einige Informationen zum Leistungsumfang des Pakets und warum es sich überhaupt lohnt, sich damit zu beschäftigen. Kernstück der Enterprise Suchmaschine ist ein Lucene SOLR Indexer (Elastic Search ist ebenfalls verwendbar), mit dem recht beliebige Dokumente indexiert werden können. Die enthaltenen Informationen werden damit als Keyword im Kontext findbar und referenzierbar. Aber OSDS ist noch wesentlich mehr. In dem Paket ist auch ein sogenanntes Open Semantic ETL (Extract-Transform-Load) Framework integriert, in dem die Texte für die Extraktion, Integration, die Analyse und die Anreicherung vorbereitet werden. Es handelt sich um eine Pipeline, die einem sehr viel von Arbeit hinsichtlich der Bereitstellung der Texte für den Indexer abnimmt. Wer mit Lucene/Solr arbeitet weiß, wie viel Zeit die Aufbereitung der Daten in der Regel beansprucht. OSDS nimmt einem viel davon ab und kümmert sich nach dem Prinzip eines überwachten Ordners um sämtliche Schritte, die von der Extraktion über die linguistische Analyse bis zur Anreicherung mit weiteren Metadaten notwendig sind. Schliesslich stellt das Paket auch einen Webservice (Rest-API) für die maschinelle Kommunikation sowie ein durchdachtes User Interface zur Verfügung, mit dem die Suchmaschine bedient, konfiguriert und natürlich auch durchsucht werden kann. Die facettierte Suche spielt dabei eine besondere Rolle, da die Facetten mehr oder weniger automatisch aus der linguistischen Analyse der Texte und auf der Grundlage von (konfigurierbaren) Namen Entities (Personen, Orte, Organisationen etc.) gebildet werden. Entsprechend sind auch die Hauptfunktionen des Softwarepakets angelegt: Sucheninterface, ein Thesaurus für Named Entities, Extraktion von Entitäten in neu zugefügten Texten, eine listenbasierte Suche sowie eine Indexfunktion, die den Aufbau des Suchindex neu anstößt. Und das alles in einem einfach zu bedienden Userinterface, das mit der Maus bedient werden kann.
Wer nun neugierig oder enthusiastisch geworden ist, dem sei gesagt, dass es wie meist im Leben einen Wermutstropfen gibt: insbesondere OSDS aber auch OSS brauchen gewisse Ressourcen, um ihre Arbeit effizient verrichten zu können. Als Mindestausstattung für einen Betrieb unter Orcale Virtual Box gebe ich 8 GB RAM und (der Größe des Projekts entsprechend) ausreichend Speicherplatz auf einer SSD an. Eventuell kann man sich, bei schwacher Hardware, eines Tricks bedienen und den Index auf einer schnellen Maschine (aktueller Mehrkernprozessor mit möglichst üppigem RAM) erstellen lassen und dann beides (Appliance und Solr-Index) auf das betreffende Gerät zurückspielen. Meist reicht dann die Performance, um zumindest die Suchfunktionalität auch auf schwächerer Hardware zu ermöglichen. Ein weiterer Ressourcenfresser beim Anlegen des Index ist OCR. OSDS hat Tesseract als eigene OCR Egine inkl. (hört hört) Frakturerkennung! integriert. Wenn man seine PDF Dokumente aber vor der Indexierung erst noch mit der OCR behandelt, kann man den Rechner bei entsprechender Materialfülle gerne mal ein oder zwei Tage beschäftigen, bevor sich (hoffentlich) ein brauchbares Ergebnis zeigt. Daher rate ich (ebenso wie der Entwickler es tut) dazu, OCR erst mal abzustellen, wenn man es nicht unbedingt braucht (geht im Konfigurationsmenue) und den Index zunächst mal nur mit schon vorhandenen Textlayern oder am besten mit Dokumenten zu füttern, die eh nur aus Text bestehen. Dabei ist die Suchmaschine recht offen für Formate und bringt eine Menge Filter mit, die den Text extrahieren können (hier mal die Liste von der Webseite kopiert: text files, Word and other Microsoft Office documents or OpenOffice documents, Excel or LibreOffice Calc tables, PDF, E-Mail, CSV, doc, images, photos, pictures, JPG, TIFF, videos and many other file formats). Im Hintergrund werkelt hier natürlich Apache Tika.