
CDH Workshop: From Letters to Data. Digitizing 19th Century Student Travelogues, Groningen, 19.6.26, 9:00-12:00h (streamed)
Antworten

„Die Reihe Digitale Geschichte(n): Projekte und Praktiken der Digital History rückt jene Vorhaben in den Mittelpunkt, in denen digitale Methoden, Quellen und theoretische Reflexionen über Digitalität miteinander verbunden werden. Sie vereint Beiträge, die zeigen, wie vielfältig und breit die Digital History heute in Forschung und Praxis verankert ist, von der datenbasierten Analyse mittelalterlicher Quellen über die Visualisierung historischer Netzwerke bis hin zur Historisierung von Digitalität selbst. […]“
Bislang sind fünf Beiträge online. Darunter auch zuletzt der spannende und sehr lesenswerte Beitrag von Christopher Pollin über seinen Weg in und mit LLMs in Digital History Projekte.

 Jörg Wettlaufer / DALL-E 2024
Jörg Wettlaufer / DALL-E 2024
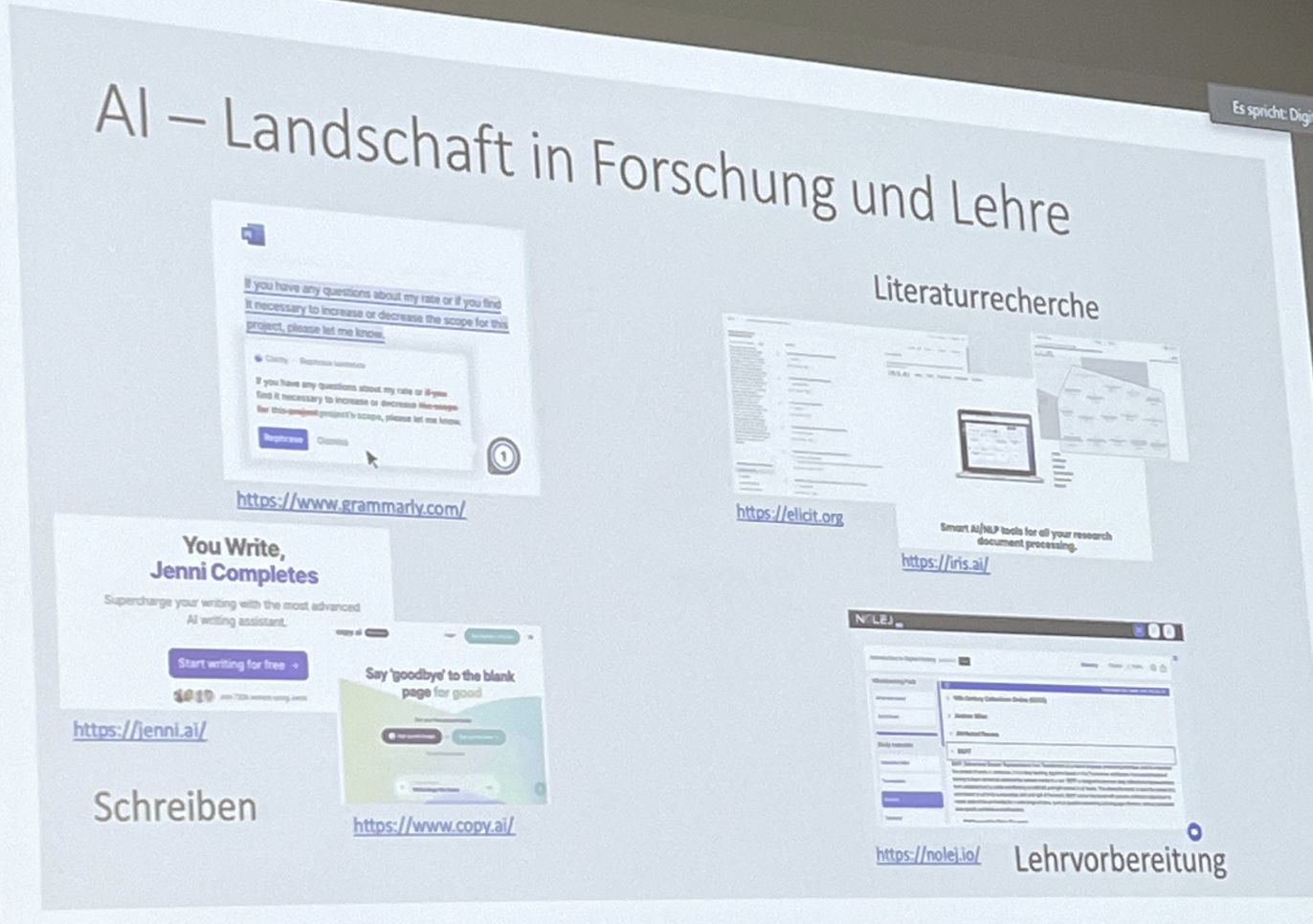
Um Methoden aus dem Bereich der Künstlichen Intelligenz adäquat in der Forschung anwenden zu können, ist es erforderlich, sie in ihren Grundzügen zu verstehen und idealerweise aktiv (spielerisch) zu erproben.
Die Themenkonferenz, die von der Akademie der Wissenschaften in Hamburg und der Niedersächsische Akademie der Wissenschaften zu Göttingen ausgerichtet wird, möchte sich diesem Spannungsfeld widmen. Teilnehmende aus den Akademievorhaben haben die Möglichkeit, die Potenziale neuer Methoden für die Analyse und Aufbereitung digitaler Ressourcen, speziell im Akademienprogramm, gemeinsam zu erörtern und zu erproben.
Das jeweils aktuelle Programm ist unter diesem Link verfügbar.
Vorläufiges Programm (Stand 20. August 2024):
Montag, 23. September 2024
ab 12:00 Ankunft der Teilnehmenden
12:45 Begrüßung
Workshop
13:00 – 17:00 Jan Kamlah, Thomas Schmidt (Mannheim)
eScriptorium
18:00 Öffentlicher Abendvortrag (Link)
Prof. Dr. Chris Biemann (Hamburg)
Where do you come from, ChatGPT? – Funktionsweise von Sprachmodellen
Dienstag, 24. September 2024
9:00 – 10:30 Integration von KI in Akademievorhaben: Projekte und Perspektiven
Matteo Burioni, Peter Bell (München)
Geplante KI-Anwendungen im Korpus der barocken Deckenmalerei
Wolfram Enßlin, Nathanael Philipp & Nadine Quenouille (Leipzig)
Forschungsportal BACH – Möglichkeiten der Integration von KI-gestützten Methoden
Jonatan Jalle Steller, Dominik Kasper (Mainz)
KI × DH: Zum Umgang mit ML, Transformern und LLMs in der Digitalen Akademie
10:30 – 11:00 Kaffeepause
11:00 – 12:30 OCR, HTR, Editionen und Urkunden
Daniel Kinitz (Leipzig)
ML-basierte Texterkennung arabographischer Handschriftenkataloge – Herausforderungen und Best Practices
Frederik Skidzun (Berlin)
Automatisierte Übersetzung von Urkundenregesten mit DeepL
Jörg Wettlaufer (Göttingen)
Custom-GPTs für die Entitäten-Erkennung und Auszeichnung
12:30 – 14:00 Mittagspause
14:00 – 15:30 Lexika, Übersetzungen und Annotation
Jan Christian Schaffert (Göttingen)
Edition, KI und Lexikographie – Wie können digitale und interdisziplinäre Zugänge zu der frühneuhochdeutschen Textwelt geschaffen werden?
Manuel Raaf (München)
Die Lemmatisierung von Zettelkästen mittels Deep Learning: Handschriftenerkennung im Fränkischen Wörterbuch
Patrick D. Brookshire (Mainz)
Namen erkennen und klassifizieren. Fine-Tuning von Transformer-Modellen
15:30 – 16:00 Kaffeepause
16:00 – 17:30 Retrieval Augmented Generation und Linked Open Data
Bärbel Kröger, Kaan Bashar (Göttingen)
Informationsextraktion aus lateinischen Texten des Repertorium Germanicum mittels Custom GPTs
Thomas Eckart, Felix Helfer, Uwe Kretschmer (Leipzig)
Machine-learning gestütztes Entity Linking
Timm Lehmberg, Stefano Valente (Hamburg)
Anwendungsbeispiel für dokumentbasiertes Parsing
19:30 Angebot einer Lichterfahrt auf der Elbe (Selbstzahler)
Mittwoch, 25. September 2024
Hands-On-Sessions
9:00 – 13:00 Timm Lehmberg (Hamburg)
Hackathon “Chat mit RAGgate”. Eigene Datenbasen mithilfe von Retrieval Augmented Generation zugänglich machen
9:00 – 13:00 Ines Röhrer (München)
Prompt-a-thon “Mein Bot versteht mich nicht!” Verarbeitung von Prompts verstehen und bessere Ergebnisse erzielen
Die Anmeldung ist für MitarbeiterInnen der Vorhaben aus dem Akademienprogramm und Akademiemitglieder online bis zum 31. August 2024 möglich unter: https://form.adwhh.de/index.php/898549?lang=de
(Vor der Anmeldung erfolgt eine Registrierung und Prüfung Ihrer E-Mail-Adresse)
Fragen zu Inhalt und Programm der Konferenz können an ki@akademie-der-wissenschaften-in-hamburg.de oder direkt an Timm Lehmberg (timm.lehmberg@awhamburg.de) gerichtet werden.
Looking forward to the DH Conference in South Corea in 2026!





Vom 24.-26.5.2023 fand in Berlin die 2. Digital History Tagung der AG Digitale Geschichtswissenschaft im VHD hybrid statt. Nachdem die erste Tagung in Göttingen noch coronabedingt zunächst abgesagt und dann 2021 als reine Online-Tagung durchgeführt wurde, hatten sich diesmal 150 TeilnehmerInnen für den Präsenzteil und nochmal eben so viele für die Onlineteilnahme angemeldet. Ausgerichtet durch die Professur für Digital History von Torsten Hiltmann und tatkräftig von Melanie Althage und Martin Dröge unterstützt, hatte sich die Community der Digitalen HistorikerInnen zu diesem dreitägigen Treffen zu dem Thema “ Digitale Methoden in der geschichtswissenschaftlichen Praxis. Fachliche Transformationen und ihre
epistemologischen Konsequenzen“ an der HU Berlin eingefunden. Tagungsprogramm und Abstracts können auf der Tagungsseite auf hypotheses.org eingesehen werden. Der Tagung vorangestellt waren Workshops und eine Studierendenkonferenz am 23.5.23.
Da ich seinerzeit in Lille die initiale Idee zu diesem Tagungsformat hatte und die Etablierung des Formats dann zusammen mit Mareike König im Komitee der AG Digitale Geschichtswissenschaft voran getrieben habe, erlaube ich mir im folgenden einen kurzen Rückblick auf die gerade stattgefundene Tagung und einen Ausblick auf das nächste, schon für 2024 geplante Treffen.
Sowohl die Zahl der Anmeldungen als auch die rege Teilnahme in Berlin selber lassen darauf schliessen, dass das Format und auch die konkrete Umsetzung erneut einem aktuellen Bedürfnis in den Digitalen Geschichtswissenschaften entsprechen, sich über Methoden und epistemiologische Konsequenzen der Digitalisierung in den Geschichtswissenschaften im Rahmen eines engeren Fachbezugs zu verständigen. Die Beiträge waren auch diesmal qualitativ ansprechend und einem hohen theoretischen Reflexionsniveau, allerdings wurde auch kontrovers z.B. über Themen wie Restitution oder Postkoloniale Forschungsmethoden diskutiert. Thematisiert wurde auch der „Elefant im Raum“, den Patrick Sahle (Wuppertal) zunächst ansprach und der von Torsten Hiltmann im Abschlussplenum mit einem kurzem Input nochmal aufgenommen wurde. Es geht dabei um Large Language Models wie ChatGPT und deren disruptive Auswirkung auf Foschung und Lehre, auch in den Geschichtswissenschaften. Da der Elefant erst nach Abschluss des CfP zu dieser Tagung in den Raum getreten war, konnte er auf der diesjährigen Tagung noch nicht entpsprechnend adressiert werden. Das wäre für das nächste Treffen in Halle 2024 sehr wünschenswert.
Die Keynote in Berlin am Mittwochabend führte die TeilnehmerInnen in die Parallelwelt des Datenjournalismus. Hendrik Lehmann vom Tagesspiegel Innovation Lab sprach über Digital Journalism: Neue Methoden für Recherche, Visualisierung und Ausspielung in der journalistischen Arbeit. Dabei war interessant, welche Tools und Methoden in diesem Bereich eingesetzt werden, die möglicherwese auch in der Geschichtswissenschaftlichen Forschung von Interesse sein könnten.

Die Postersession der diesjährigen Tagung diente auch zur Vorauswahl der Finalisten für den Peter Haber Preis, der auf dem diesjährigen Historikertag in Leipzig vergeben wird. Sieben von dreizehn Poster wurden in einer kombinierten Publikums- und Juryabstimmung ausgewählt. Die Poster können auf dieser Seite online angeschaut werden. Gelungen war auch die Spreefahrt am Donnerstag, auf der die Diskussion vor der Kulisse der Hauptstadt und fortgesetzt werden konnte.

Zum Abschluss der Tagung erfolgte die Einladung zum nächsten Treffen in Halle im September 2024. Das Thema dort wird „Citizen Science“ sein und von Katrin Möller und KollegInnen von dem dortigen Datenzentrum ausgerichtet. Das Komitee der AG Digitale Geschichtswissenschaft freut sich schon auf Bewerbungen für die nächsten Tagungen, die dann im Wechsel mit dem Historikertag voraussichtlich 2026 und 2028 stattfinden werden.

Der Begriff des Data Stewards ist seit einigen Jahren in aller Munde, aber bislang weiss man nicht genau, was man sich darunter eigentlich vorzustellen hat und welchen Aufgabenbereich dieser Beruf genau abdeckt. An der Uni Köln wurden nun Informationen aus einem Projekt veröffentlicht, in dem diese Frage untersucht wurde. Ein Ergebnis war, dass es unterschiedliche Profile dieser neuen Berufsbezeichnung gibt, die unterschiedliche Aufgabenfelder des Data Management adressieren.
1. Data Stewards als GeneralistInnen
2. Zum allgemeinen Forschungsdatenmanagement beratende Data Stewards
3. Disziplinär-betreuende Data Stewards
4. Data Stewards als Koordinator:innen
5. Informationsinfrastrukturnahe Data Stewards
Die Ergebnisse der Studie finden sich in diesen Publikationen:
· Forschung unterstützen: Empfehlungen für Data Stewardship an akademischen Forschungsinstitutionen – Ergebnisse des Projektes DataStew<https://doi.org/10.4126/FRL01-006441397>
· Datastewardship in Deutschland – Bestandsaufnahme, Empfehlungen und Ausblick.<https://youtu.be/-qmJKmUpQ0Y> Ein Interview mit Dr. Jens Dierkes, Fabian Hoffmann und Dr. Eva Seidlmayer aus dem DataStew-Projektteam
· Data Steward: ein Berufsbild so facettenreich wie die Einsatzbereiche<https://www.zbmed.de/fileadmin/user_upload/Pressemitteilungen/2023/2023-05-02_pm_DataStew.pdf>
· Projekt DataStew<https://www.zbmed.de/forschen/abgeschlossene-projekte/datastew>
Der Sammelband unserer gleichnamigen Tagung 2018 am ZIF Bielefeld ist gedruckt und erscheint Ende März 2023. Herzlichen Dank an alle UnterstützerInnen und BeiträgerInnen!

This book seeks to bring comparative perspective to the idea that honor and shame are two fundamentally important and closely related concepts of human social experience with a diverse and important history. Both vital responses are rooted in the social existence of mankind – human life is embedded in social interaction, attribution of respect and contempt. The book addresses the relevance and manifold manifestations of honor and shame in Western History in three parts, covering concepts and challenges of honor and shame, honor and shame in traditional European societies and honor and shame in modernity. The contributions cover Western history from Greek and Roman times to the 19th century and they make evident that the drive to acquire and uphold honor and to scrupulously avoid shame have been of tremendous influence for the social makeup of past societies from the dawn of humankind on into the ‘postmodern’ world of social interaction. “Honor and Shame in Western History” brings together fourteen contributions of interdisciplinary scholars from Europe and North America on the topic. The book is suited for a broad audience interested in European social history and the history of emotions.
Wenn man dieser Tage seine Twitter Timeline anschaut, dann sprechen sich viele Kolleginnen und Kollegen dafür aus, nach dem Kauf von Twitter durch Elon Musk nun zum kleinen aber feinen Anbieter Mastodon aus Jena zu wechseln. Der Vorteil hierbei ist, dass es sich um ein verteiltes Microblogging Netzwerk handelt. Wenn man sich anmelden möchte, dann stellt sich zunächst die Frage, auf welchem Server man das tut. Steffen Voß, den ich noch aus Kieler Webmontag Zeiten kenne, hat eine kleine Anleitung dazu auf seinem Blog Kaffeeringe.de gepostet, die eine erste Hilfestellung dazu gibt. Ich würde mir wünschen, dass eine der IT Infrastruktureinrichtungen in Deutschland hier in die Bresche springen und einen entsprechenden Server mit Fokus auf die Wissenschaftskommunikation bereit stellen würde. Da könnten sich dann bevorzugt alle diejenigen anmelden, die Twitter bislang vor allem im Bereich der Wissenschaft verwendet haben.
Update 24.11.22:
Meine Bitte wurde erhört. 🙂 Inzwischen gibt es auch schon detaillierte Anleitungen, wie man z.B. auf fedihum.org einen Mastodon Account anlegen kann. Hier die ausführliche Anleitung von Mareike König auf hypotheses.org.
Tröten über Droysen: ein Mastodon-Leitfaden für Historiker:innen
Abstract: „[…] This study reflects some preliminary observations resulting from our digital history project that aims at building and digitally analyzing an extensive corpus
of English-, French-, and German-language travelogues about the nineteenthcentury
Ottoman Empire. It discusses our initial findings in travelogues regarding
the sociopolitical dynamics of the rise of Middle Eastern nationalisms and
our methodological suggestions about the opportunities as well as challenges
of employing digital tools to use travelogues for historical analysis. The chapter
starts with a discussion on nations and nationalisms in the nineteenth-century
Middle East, particularly in the Ottoman Empire. Then it deals with the question
of using travelogues as historical sources, focusing on the history of nationalisms,
and suggests that digital history tools are essential for increasing the reliability
of this body of sources. Finally, we present our findings and suggestions
on how and what kind of digital history tools can be used to open such corpora
to historical research.“
See also the project website:

Band 6 der Reihe „Studies in Digital History and Hermeneutics“ ist erschienen. Es handelt sich um den Tagungsband der Digital History Tagung, die die HerausgeberInnen im Frühjahr 2021 in Göttingen virtuell organisiert haben. Das Buch ist am 31. August 2022 Open Access erschienen! https://doi.org/10.1515/9783110757101 Enjoy.
