Graz ist immer eine Reise wert. Seit es das Zentrum für Informationsmodellierung an der dortigen Universität gibt, ist fast umungänglich geworden mindestens einmal im Jahr dort vorbei zu schauen. Eine gute Gelegenheit dazu war die Tagung „Digital Scholarly Editions as Interfaces„, die vom 23. bis 24. September 2016 in Graz direkt vor der TEI Tagung in Wien stattfand. Mit über 100 Anmeldungen war die Tagung gut besucht und vor allem auf der Seite der Redner sehr international besetzt. Tagungssprache war Englisch. Gesponsert und auch organisiert wurde die Veranstaltung von dixit, dem „Digital Scholarly Editions Initial Training Network“. Ich erlaube mir im folgenden nur meine „persönlichen“ Highlights herauszupicken und näher zu besprechen. Das Niveau der Vorträge war insgesamt hoch und die Teilnahme auf jeden Fall ein Gewinn. Ich bin schon gespannt, welche Veranstaltung mich als nächstes nach Graz lockt.
Die Tagung begann mit einer Keynote von Dot Porter (University of Pennsylvania), die sich ganz grundsätzlich mit der Frage: „What is an Edition anyway? A critical examination of Digital Editions since 2002“ beschäftigte. Im Mittelpunkt ihres Vortrags standen mehrere Umfragen, die sie seit Anfang der 2000er Jahre in der DH community durchführt und die sich mit der Verwendung von digitalen Editionen durch Wissenschaftlerinnen und Wissenschaftler beschäftigen. Zentral ist dabei die Unterscheidung zwischen digitalisierten und digitalen Editionen, also den „nur“ in digitalem Format angebotenen gedruckten Editionen und den ohne Druckvorlage, rein digital erstellen Editionen. Die neueste Umfrage unter Mediaevisten im September 2016 erbrachte die folgende, interessante Nutzerstatistik:

Repräsentativ oder nicht, die Statistik weist zumindest auf einen hohen Anteil der Nutzung von digitalisierten und gedruckten Editionen bei solchen Personen hin, die häufig oder dauernd diese Textsorte verwenden. Damit bleibt die rein digitale Edition weiterhin ein Experimentierfeld, in dem sich erst noch Standards herausbilden und etablieren müssen. Dazu trägt sicher die Zeitschrift ride (Review Journal for digital Editions and Ressources) bei, das seit einigen Jahren versucht Standards in diesem Bereich zu schaffen.
Schon in diesem ersten Beitrag wurde am Ende eine Dichotomie zwischen Interface und Text postuliert, die im Anschluss in einer Reihe von Beiträgen wieder aufgenommen wurde. Interface over Text oder Text over Interface – diese Frage nahmen einige Vorträge gerne wieder auf und gaben ihre subjektive Antwort.
In den nun folgenden Sessions des ersten Tages fielen eine Reihe von Vorträgen wg. kurzfristiger Absagen aus, so dass eine intensive Diskussion der übrigen Beiträge möglich wurde. Eugene W. Lyman (Independent Scholar) wies die Teilnehmer auf die Relevanz von Verläßlichkeit bei Editionen, seien sie digital oder analog, hin. Dies würde, bei einer Konzentration auf Interfaces, leider schnell übersehen (Digital Scholarly Editions and the Affordances of Reliability). Christopher M. Ohge (University of California, Berkeley) stellte dann die erste konkrete Edition, die Notizbücher von Mark Twain, vor (http://www.marktwainproject.org/). Sein Vortrag war mit „Navigating Readability and Reliability in Digital Documentary Editions“ überschrieben und so nahm somit die oben gestellte Frage nach Interface und Verläßlichkeit des Texts auf. Die folgenden Vorträge wandten sich Themen der Visualierung, Typhographie und des Designs von Digitalen Editionen zu und dieser Komplex wurde abgerundet durch eine Keynote von Stan Ruecker (ITT Institute of Design, Chicago), die den ersten Tag beschloss. Es ist ein Verdienst der Tagung, dass konkret Designer eingeladen wurden (auch wenn am Ende nur wenige anwesend waren) und ihre Perspektive auf Digitale Editionen mitteilen konnten. Nur allzu oft bleibt dieser Aspekt aus Kostengründen oder Ignoranz bei wissenschaftlichen Editionen unberücksichtigt – mit den uns allen bekannten Folgen und Effekten. In diesem Zusammenhang wurden auch agile Methoden bei Design und Software-Entwicklung vorgestellt – inzwischen Standards im freiberuflichen Feld, aber bei weitem noch nicht Standard in den Geisteswissenschaften und den Digital Humanities.

Der zweite Tag begann mit einer „Nerd-Session“, in der mehr technische Fragen der Programmierung und Entwicklung von Interfaces für Digitale Editionen thematisiert wurden. Hugh Cayless (Duke University Libraries) startete mit einem Vortrag über
„Critical Editions and the Data Model as Interface“, in dem er eine Edition von lateinischen Texten vorstellte, die nicht auf TEI und XSLT Transformationen beruht, sondern über Javascript verschiedene Sichten auf Text ermöglicht. Seine Slides und eine Demo sind unter https://goo.gl/q7kbY0 abrufbar. Chiara Di Pietro (University of Pisa) und Roberto Rosselli Del Turco (University of Turin) sprachen anschliessend über „Between innovation and conservation: the narrow path of UI design for the Digital Scholarly Edition“ und stellten dabei die Version 2.0. des bekannten EVT-Editionstools vor.
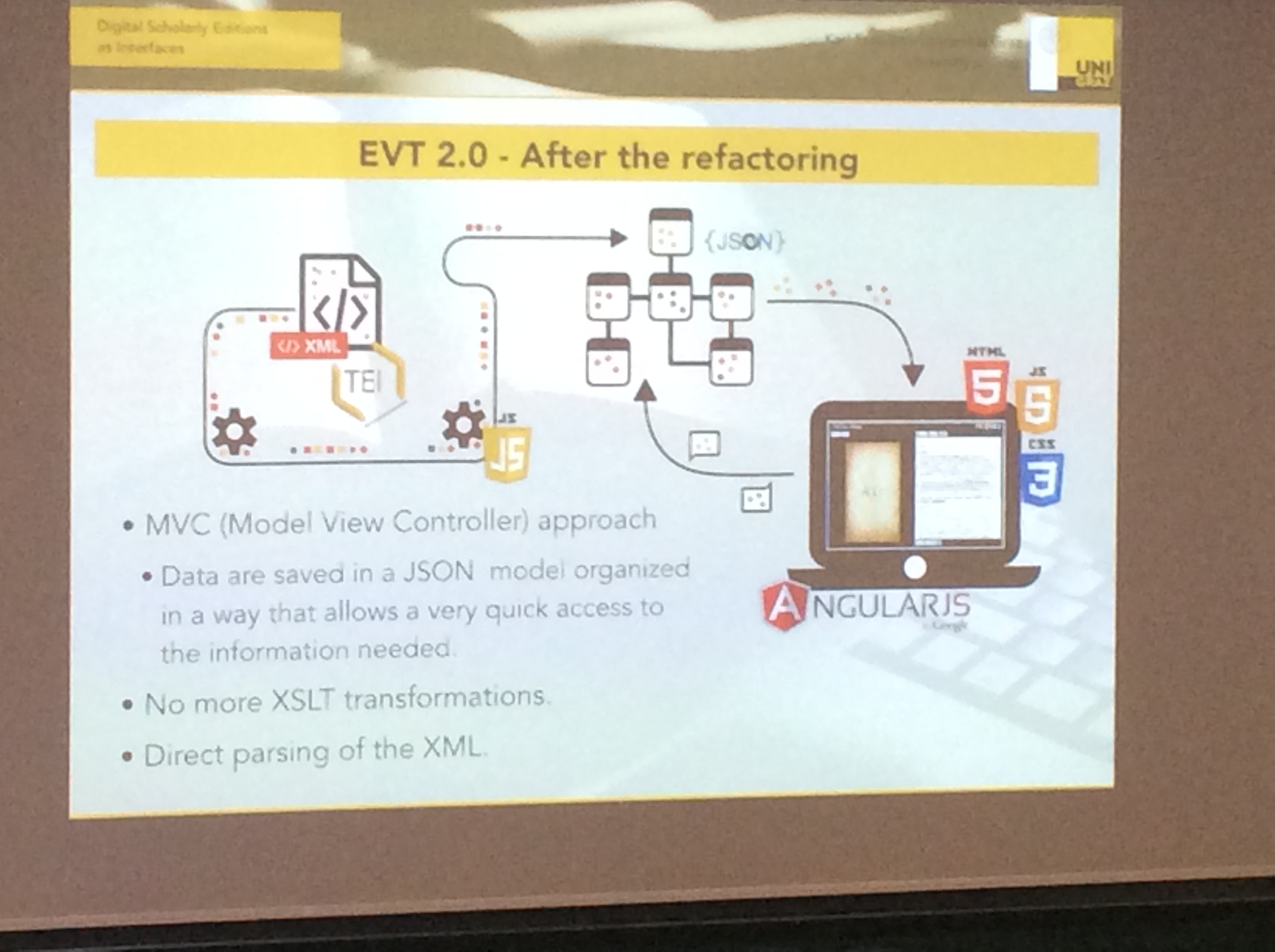

Der dritte talk der Session ist mein persönlicher Spitzenreiter der Tagung.
Jeffrey C. Witt (Loyola University Maryland) sprach nicht nur kompetent sondern auch sehr anschaulich über „Digital Scholarly Editions as API Consuming Applications“ und stellte verschiedene LOD-Lösungen vor, die unter Einbeziehung des IIIF Standards ganz neue Möglichkeiten der Integration und Präsentation von Daten ermöglichen. Sein Vortrag und viele Beispiele finden sich auf http://lombardpress.org/. Ich sehe hier in der Tat eine wichtige Perspektive für die Zukunft der digitalen Editionen, die ja auch im MEDEA Projekt (modelling semantically enriched editions of accounts) anklingt, das leider auf der Tagung nicht vorgestellt wurde, aber dessen Protagonisten anwesend waren.
Die weitere Talks des zweiten Tages widmeten sich theortischen Implikationen und nahmen die Frage der Dichotomie von Interface und Edition wieder auf. Peter Robinson (University of Saskatchewan) schlug sich dabei ganz auf die Seite der Editionen (Why Interfaces Do Not and Should Not Matter for Scholarly Digital Editions), während Tara Andrews (Univ. Wien) und Joris van Zundert (Huygens Institute for the History of The Netherlands) die Seite der Intefaces mit einem Beitrag über das „Interface als Integrales Elements des Arguments einer Edition“ stark machten. Der Nachmittag war den anwenderorientierten Lösungen gewidment und es wurden Themen wie user-centred design und co-creation Ansätze diskutiert. Die Liste der Beiträge und ein Abstraktheft ist auf den Seiten des Grazer Instituts für Informationsmodellierung abrufbar. Im Fazit war dies eine Tagung, die die weite Anreise gelohnt hat und, wie schon oben erwähnt, Lust auf die nächste Reise nach Graz macht, zum Beispiel zur Digital Libraries Tagung 2017, die vom 2.-3. März 2017 ebendort stattfinden wird und deren CFP just gestern abgelaufen ist.
Jörg Wettlaufer, Göttingen